Introduction
As businesses increasingly depend on digital services, the expectations for application availability, performance, and reliability have never been higher. Customers expect systems to remain accessible around the clock, while organizations strive to release new features rapidly without compromising stability. Achieving both speed and reliability requires more than traditional IT operations—it requires a disciplined approach to engineering reliability into every stage of the software lifecycle.
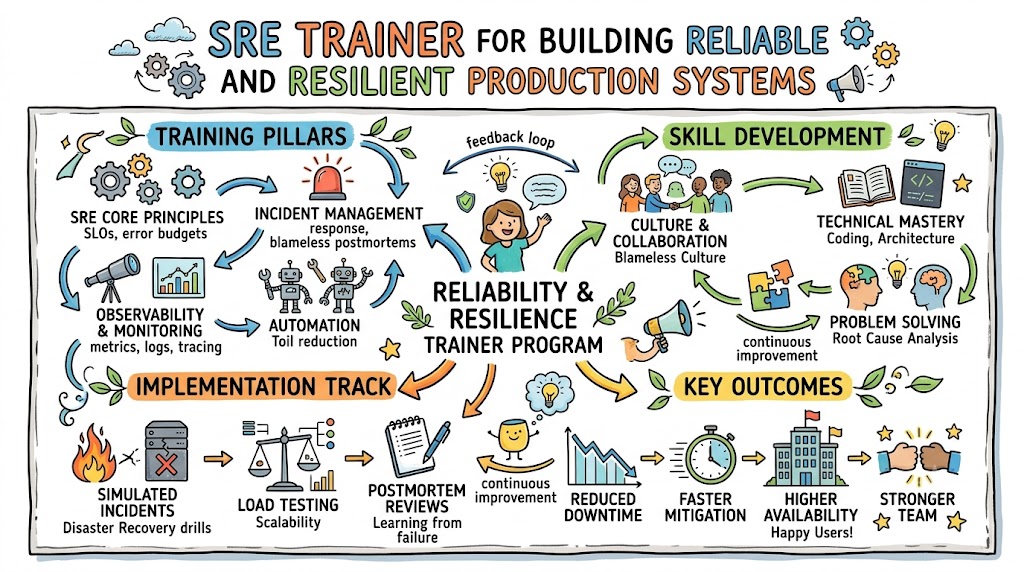
This is where Site Reliability Engineering (SRE) has become a critical practice. By combining software engineering principles with operations, automation, monitoring, and incident management, SRE enables organizations to build production systems that remain resilient under changing workloads and unexpected failures.
An experienced SRE Trainer helps engineers, DevOps professionals, platform teams, and IT leaders understand how to design, operate, and continuously improve highly available production environments. Practical Site Reliability Engineering Training equips teams with the skills needed to improve service reliability, automate repetitive tasks, monitor system health, and respond effectively to incidents.
Rajesh Kumar has extensive experience helping technology professionals and enterprise organizations strengthen their capabilities across DevOps, Kubernetes, Site Reliability Engineering, DevSecOps, Platform Engineering, cloud automation, Infrastructure as Code, CI/CD, GitOps, Terraform, and Jenkins. His practical approach focuses on solving real production challenges rather than simply explaining theoretical concepts. Organizations interested in learning more about his training and consulting services can visit https://www.rajeshkumar.xyz/.
This article explains why SRE has become an essential discipline for modern IT organizations and how professional training helps build reliable and resilient production systems.
Who Is Rajesh Kumar?
Rajesh Kumar is an experienced technology mentor, DevOps Trainer, SRE Trainer, SRE Consultant, Kubernetes Trainer, DevSecOps Trainer, Platform Engineering Consultant, Cloud DevOps Consultant, and AWS DevOps Consultant. He works closely with enterprise engineering teams to help them adopt modern software delivery practices that improve operational excellence, automation, and system reliability.
His expertise includes:
- Site Reliability Engineering Training
- DevOps implementation
- Kubernetes orchestration
- Docker Kubernetes Training
- CI/CD Pipeline Training
- GitOps Training
- Terraform Training
- Jenkins Training
- DevSecOps Corporate Training
- Platform Engineering Training
- Cloud infrastructure automation
- Production operations and observability
Rather than focusing solely on certifications, his training emphasizes practical implementation using real-world production scenarios and enterprise best practices.
Understanding Site Reliability Engineering
Site Reliability Engineering is a discipline that applies software engineering principles to IT operations. Instead of relying heavily on manual processes, SRE emphasizes automation, observability, measurement, and continuous improvement to maintain reliable services.
The primary goals of SRE include:
- Improving system reliability
- Automating operational tasks
- Reducing downtime
- Managing incidents effectively
- Optimizing system performance
- Supporting faster software delivery
- Enhancing user experience
- Building scalable production platforms
SRE enables organizations to balance innovation with operational stability by establishing measurable reliability objectives.
Why Organizations Need an Experienced SRE Trainer
As infrastructure becomes increasingly distributed across cloud environments, managing production systems requires specialized skills. An experienced SRE Trainer helps organizations develop these capabilities through structured, practical learning.
Professional Site Reliability Engineering Training enables teams to:
- Understand production reliability principles
- Build monitoring and observability solutions
- Define service reliability objectives
- Automate repetitive operational tasks
- Improve incident response
- Optimize system performance
- Reduce operational risk
- Establish a culture of continuous improvement
Training also helps engineers adopt proactive operational practices instead of relying on reactive troubleshooting.
SRE Consultant for Operational Excellence
An experienced SRE Consultant helps organizations improve the reliability and efficiency of their production environments by evaluating existing operational processes and recommending practical improvements.
Consulting activities often include:
Reliability Assessment
Evaluating production environments to identify potential risks and operational bottlenecks.
Service Level Objectives
Helping organizations define realistic Service Level Indicators (SLIs), Service Level Objectives (SLOs), and error budgets to measure system performance effectively.
Incident Management
Designing structured incident response processes that reduce downtime and improve collaboration during production issues.
Automation Strategy
Replacing repetitive manual operations with automated workflows to improve efficiency and reduce operational errors.
Continuous Improvement
Establishing feedback mechanisms that help engineering teams learn from incidents and improve operational practices over time.
Core Topics Covered in Site Reliability Engineering Training
A comprehensive Site Reliability Engineering Training program covers both foundational concepts and practical implementation.
Service Level Indicators (SLIs)
SLIs measure critical aspects of system performance such as:
- Availability
- Latency
- Throughput
- Error rates
These metrics provide objective insights into service health.
Service Level Objectives (SLOs)
SLOs define measurable reliability targets that engineering teams aim to achieve. Clear objectives help balance innovation with operational stability.
Error Budgets
Error budgets help organizations determine how much operational risk is acceptable while continuing to deliver new features.
Monitoring and Observability
Training introduces modern observability practices including:
- Metrics collection
- Log aggregation
- Distributed tracing
- Dashboard creation
- Alert management
Effective observability enables engineers to detect issues before they impact users.
Incident Management
Participants learn structured approaches for:
- Incident detection
- Incident response
- Escalation procedures
- Root cause analysis
- Post-incident reviews
These practices reduce recovery time and strengthen operational resilience.
DevOps and SRE: Working Together
While DevOps focuses on improving collaboration and accelerating software delivery, SRE emphasizes maintaining system reliability throughout that delivery process.
A strong SRE practice complements DevOps by introducing:
- Automation
- Reliability engineering
- Production monitoring
- Capacity planning
- Performance optimization
- Operational metrics
- Failure recovery
- Continuous improvement
Organizations benefit when DevOps and SRE work together to balance speed with stability.
Kubernetes and Site Reliability Engineering
Modern SRE teams frequently manage Kubernetes-based production environments.
An experienced Kubernetes Trainer helps engineers understand how Kubernetes supports reliable application delivery through:
- Self-healing workloads
- Automatic scaling
- Rolling updates
- Health checks
- Resource optimization
- High availability
- Service discovery
- Container orchestration
Combining Kubernetes expertise with SRE principles creates highly resilient cloud-native platforms.
CI/CD Pipeline Training for Reliable Deployments
Reliable software delivery depends on consistent automation. Professional CI/CD Pipeline Training teaches engineers how to automate application builds, testing, and deployments while reducing production risks.
Training covers:
- Continuous Integration
- Continuous Delivery
- Automated testing
- Deployment automation
- Release validation
- Rollback strategies
- Pipeline monitoring
- Deployment consistency
These practices improve release quality while supporting rapid software delivery.
Terraform Training for Infrastructure Reliability
Infrastructure reliability begins with Infrastructure as Code.
Professional Terraform Training enables engineers to provision cloud infrastructure consistently using version-controlled code.
Topics include:
- Infrastructure provisioning
- State management
- Modules
- Variables
- Cloud automation
- Kubernetes infrastructure
- Resource management
- Infrastructure consistency
Automated infrastructure reduces configuration drift and improves operational reliability.
Jenkins Training for Production Automation
Automation is a key principle of Site Reliability Engineering.
Professional Jenkins Training helps organizations automate repetitive software delivery tasks including:
- Build pipelines
- Test execution
- Deployment automation
- Release workflows
- Pipeline monitoring
- Artifact management
- Kubernetes deployments
- Integration with cloud platforms
Automation improves consistency while reducing manual operational effort.
GitOps Training for Reliable Infrastructure Management
GitOps has become an important operational model within Kubernetes environments.
Professional GitOps Training introduces practices such as:
- Git as the source of truth
- Infrastructure version control
- Automated synchronization
- Configuration consistency
- Rollback automation
- Auditability
- Continuous reconciliation
GitOps simplifies operations while improving production reliability.
DevSecOps for Secure Production Systems
Reliable systems must also be secure. Professional DevSecOps Corporate Training teaches organizations how to integrate security into automated delivery pipelines.
Topics include:
- Secure CI/CD
- Container security
- Secret management
- Vulnerability scanning
- Compliance automation
- Policy enforcement
- Runtime security
- Secure software delivery
Security becomes a continuous engineering practice rather than a separate operational stage.
Platform Engineering and Production Reliability
Many organizations are investing in internal developer platforms to improve operational consistency.
Platform Engineering Training focuses on:
- Self-service infrastructure
- Standardized deployment workflows
- Shared platform services
- Automation frameworks
- Developer enablement
- Kubernetes platform management
- Operational consistency
- Scalable engineering practices
A skilled Platform Engineering Consultant helps organizations build platforms that improve productivity while reducing operational complexity.
Cloud DevOps Consultant and AWS DevOps Consultant
Modern production systems often operate across public cloud platforms.
An experienced Cloud DevOps Consultant helps organizations:
- Automate cloud infrastructure
- Improve cloud operations
- Modernize deployment workflows
- Implement Infrastructure as Code
- Optimize cloud resources
- Strengthen monitoring
Similarly, an AWS DevOps Consultant supports AWS-based environments by improving deployment automation, cloud scalability, Kubernetes integration, and production reliability.
Tools and Technologies Covered
| Area | Tools / Topics | Business Value |
|---|---|---|
| Terraform Training | Infrastructure as Code | Reliable cloud infrastructure |
| Jenkins Training | CI/CD Automation | Consistent software delivery |
| CI/CD Pipeline Training | Build, Test, Deploy | Faster and safer releases |
| GitOps Training | Git, Argo CD | Reliable infrastructure management |
| Docker Kubernetes Training | Docker, Kubernetes | Cloud-native application delivery |
| AWS DevOps | AWS Automation | Scalable cloud operations |
| Monitoring & Observability | Prometheus, Grafana, Logging | Production visibility |
| DevSecOps | Security Automation | Secure deployments |
| Site Reliability Engineering | SLI, SLO, Incident Response | Operational excellence |
| Platform Engineering | Internal Developer Platforms | Developer productivity |
Why Choose Rajesh Kumar for Training and Consulting?
Organizations benefit from trainers who combine technical depth with practical production experience.
Reasons professionals choose Rajesh Kumar include:
- Extensive enterprise technology experience
- Practical, hands-on learning methodology
- Strong expertise across DevOps, Kubernetes, and SRE
- Production-focused examples
- Real-world troubleshooting guidance
- Broad cloud-native technology knowledge
- Focus on automation and operational excellence
- Experience supporting enterprise engineering teams
- Comprehensive understanding of modern DevOps practices
- Commitment to helping professionals build long-term technical capability
Best Fit Audience
This training is ideal for:
- DevOps Engineers
- Site Reliability Engineers
- Cloud Engineers
- Platform Engineers
- Software Developers
- Infrastructure Engineers
- IT Managers
- Engineering Managers
- Enterprise Operations Teams
- Startup Technology Teams
- Cloud Migration Teams
- Corporate Learning Programs
- Digital Transformation Initiatives
Business Benefits of Site Reliability Engineering Training
Organizations investing in SRE capability development often achieve significant operational improvements.
Key benefits include:
- Improved production stability
- Reduced downtime
- Faster incident response
- Better automation
- Improved observability
- Higher service availability
- Stronger collaboration across engineering teams
- Better deployment quality
- More efficient cloud operations
- Increased customer satisfaction
These outcomes help organizations deliver reliable digital services while supporting continuous innovation.
Frequently Asked Questions
1. Why should companies hire an SRE Trainer?
An experienced SRE Trainer helps engineering teams build reliable production systems through practical training in monitoring, automation, incident management, and operational excellence.
2. What does an SRE Consultant do?
An SRE Consultant helps organizations improve production reliability by designing better operational processes, implementing observability, automating repetitive tasks, and strengthening incident response.
3. Who should attend Site Reliability Engineering Training?
DevOps engineers, cloud engineers, platform engineers, operations teams, software developers, infrastructure teams, and enterprise IT professionals benefit from structured SRE training.
4. How does Kubernetes support Site Reliability Engineering?
Kubernetes provides automation, self-healing, scaling, and high availability features that align closely with SRE objectives for building resilient production systems.
5. Why is observability important in SRE?
Observability enables engineering teams to monitor system health, identify performance issues quickly, reduce downtime, and make informed operational decisions based on real-time data.
Conclusion
Building reliable production systems requires more than deploying modern infrastructure—it requires engineering discipline, automation, observability, and continuous improvement. Site Reliability Engineering provides the framework that enables organizations to achieve these goals while maintaining rapid software delivery.
An experienced SRE Trainer helps engineering teams develop practical skills in reliability engineering, monitoring, automation, incident management, Kubernetes, DevOps, and cloud operations. Combined with expertise in Platform Engineering, DevSecOps, CI/CD, Terraform, Jenkins, and GitOps, structured training empowers organizations to build resilient, scalable, and high-performing production environments.
To learn more about Rajesh Kumar’s professional training, consulting, and mentoring services, visit https://www.rajeshkumar.xyz/.